MongoDB保姆级指南(上):七万字从零到进阶,助你掌握又一款强大的NoSQL!
前言
在早期的程序开发过程中,单体+ MySQL足以应对业务需求,可随着业务不断发展,系统架构演变成分布式,而数据存储的需求亦是多样化,单纯依赖于MySQL或其他某一款关系型数据库,再也难以支撑系统的存储需求,于是,现如今一个复杂系统中,可能会牵扯到MySQL、Redis、ES、MongoDB、FastDFS、CDH……多种数据存储产品,根据不同的业务特性、响应要求,会将数据存储在不同组件中以满足系统需要。
MongoDB是数据库家族中的一员,是一款专为扩展性、高性能和高可用而设计的数据库,它可以从单节点部署扩展到大型、复杂的多数据中心架构,也能提供高性能的数据读写操作;而且提供了数据复制、无感知的故障自动选主等功能,从而实现数据节点高可用。
但MongoDB并不是一款关系型数据库,而是一款基于“分布式存储”的非关系型数据库(NoSQL),由C++编写而成。它与Redis、Memcached这类传统NoSQL不同,MongoDB具有半结构化特性,啥意思呢?下面仔细聊聊。
声明:相较于以往技术文,本篇内容不算特别有趣,如若各位小伙伴有足够的摸鱼时间,可以玩玩作为技术储备;反之,如果目前时间不算充裕,可以收藏等到往后有所需要时再回来阅读~
关于MongoDB相关的文章,总共会分为上中下三篇,同时为了屏蔽语言之间的差异,前面两篇都会使用MongoDB原生的语法进行阐述,为此,无论你是Java,还是PHP、Node、Go、Python、C#……任何语言的开发者,都可以畅通无阻般阅读!
一、MongoDB快速入门
MongoDB的数据存储格式非常松散,采用“无模式、半结构化”的思想,通过BSON格式来存储数据。
BSON的全称为Binary JSON,翻译过来是指二进制的JSON格式,在存储和扫描效率高于原始版JSON,但是对空间的占用会更高。同时,BSON在JSON基础之上,多加了一些类型及元数据描述,具体可参考《MongoDB官网-BSON类型》。
之所以说MongoDB具有半结构化特性,这是由于BSON拥有着JSON的特性,JSON天生具备结构性,可以便捷的存储复杂的结构数据。但是Mongo的数据结构又特别灵活,没有关系型数据库那种“强结构化”的规范。
强结构化:所有数据入库前,库中必须先定义好结构,并且入库的数据,每个值要与定义好的字段一一对应,当结构发生变更时,再按原有结构插入数据则会报错,必须同步修改插入的数据,使用起来特别“繁琐”。
MongoDB中用BSON来存储数据,而BSON是一种文档,所以它也被称之为:文档型数据库,文档由一或多个K-V键值对组成,其中的Key只能由字符串表示,值则可以是任意类型,如数组、字符串、数值……。简单来说,你可以把MongoDB中的一个文档,看做成一个JSON对象。
上面提到“文档”这个概念,初次接触的伙伴或许会疑惑,这里我们与MySQL数据库对比一下,其实两者的结构很类似,如下:
| MySQL | MongoDB |
|---|---|
数据库(DataBase) | 数据库(DataBase) |
数据表(Table) | 数据集合(Collection) |
数据行(Row) | 数据文档(Document) |
列/字段(Column) | 字段(Field) |
索引(Index) | 索引(Index) |
MongoDB中的一个集合,对应MySQL中的一张表;一个文档对应着MySQL一行数据……,层级结构的理念相同,只不过叫法和细节不同。当然,光看概念也很难帮大家认识Mongo,接下来快速搭建下环境,实操理解的效果更佳。
1.1、MongoDB环境搭建
MongoDB分为免费社区版、收费企业版,虽说前者功能有所阉割,但好在免费,并且可以满足大多数项目需求,这里咱们先去MongoDB官网-社区版选择对应的操作系统、版本下载安装包,同Redis一样,版本号的第二位数,为奇数代表开发版,为偶数代表是稳定版,我这里选择下载CentOS7-x64-6.0.8-tgz版的安装包。
❶ 创建MongoDB目录,并通过工具上传安装包至服务器(或虚拟机):
[root@~]# mkdir /soft && mkdir /soft/mongodb/
[root@~]# cd /soft/mongodb/
如果不想这么麻烦,也可以用wget命令在线拉取安装包:
[root@~]# wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-6.0.8.tgz
没有wget命令,可以通过yum安装一下:
[root@~]# yum -y install wget
❷ 解压相应目录下的安装包,并重命名解压后的目录:
[root@~]# tar -xvzf mongodb-linux-x86_64-rhel70-6.0.8.tgz
[root@~]# mv mongodb-linux-x86_64-rhel70-6.0.8 mongodb6.0.8
由于我们下载的是压缩包,属于开箱即用版,无需任何额外配置。但为了方便启动,咱们可以将bin目录拷贝出来:
[root@~]# cp -a /soft/mongodb/mongodb6.0.8/bin /soft/mongodb/bin
❸ 创建单机版MongoDB存储配置文件、数据、日志的目录:
[root@~]# mkdir /soft/mongodb/data &&
mkdir /soft/mongodb/log &&
mkdir /soft/mongodb/conf &&
mkdir /soft/mongodb/data/standalone &&
mkdir /soft/mongodb/log/standalone &&
mkdir /soft/mongodb/conf/standalone
❹ 编写MongoDB核心配置文件(没有会自动创建):
[root@~]# vi /soft/mongodb/conf/standalone/mongodb.conf
这里大家可以直接复制下述yaml配置,配置的具体含义可参考注释(也支持传统.conf形式配置):
# MongoDB日志存储相关配置
systemLog:
# 将所有日志写到指定文件中
destination: file
# 记录所有日志信息的文件路径
path:"/soft/mongodb/log/standalone/mongodb.log"
# 当服务重启时,将新日志以追加形式写到现有日志尾部
logAppend:true
# 指定MongoDB存储数据的目录
storage:
dbPath:"/soft/mongodb/data/standalone"
# 以后台进程方式运行MongoDB服务
processManagement:
fork:true
# ------ MongoDB网络相关配置 ------
net:
# 绑定服务实例的IP,默认是localhost,0.0.0.0表示任意IP(线上换成具体IP)
bindIp:0.0.0.0
#绑定的端口,默认是27017
port: 27017
复制时记住把数据、日志的目录,改成自己前面新建的,接着按下Esc,输入:wq保存退出。
❺ 启动Mongo服务,这里和Redis类似,都是以启动脚本+配置文件的方式:
[root@~]# /soft/mongodb/bin/mongod -f /soft/mongodb/conf/standalone/mongodb.conf
看到successfully表示启动成功,大家也可以通过ps命令来查看后台进程,确保正常启动:
[root@~]# ps aux | grep mongod
❻ 连接MongoDB测试是否可以正常使用,不过下述命令只适用于6.x以下:
[root@~]# /soft/mongodb/bin/mongo -port 27017
到了MongoDB6.x版本,官方不再默认内置Shell客户端工具,想要使用则需额外下载:官方Shell工具,这里咱们照样以wget方式下载:
[root@~]# wget https://downloads.mongodb.com/compass/mongosh-1.10.3-linux-x64.tgz
接着将其解压,并拷贝bin目录下的Shell工具,放到原本的bin目录中:
[root@~]# tar -zxvf mongosh-1.10.3-linux-x64.tgz
[root@~]# cp /soft/mongodb/mongosh-1.10.3-linux-x64/bin/mongosh /soft/mongodb/bin/
然后再通过mongosh来连接测试:
[root@~]# /soft/mongodb/bin/mongosh -port 27017
test> show dbs;
如果上述操作执行完成后,能正常显示三个默认库,说明MongoDB安装成功。
❼ 关闭MongoDB服务,这里有三种方式:
# 1.通过启动项来关闭
[root@~]# /soft/mongodb/bin/mongod --shutdown -f /soft/mongodb/conf/standalone/mongodb.conf
# 2.先通过客户端连接MongoDB服务,再进入admin库关闭(执行完后客户端会报连接出错)
[root@~]# /soft/mongodb/bin/mongosh -port 27017
test> use admin;
test> db.shutdownServer();
# 3.通过kill命令+进程号强杀进程
[root@~]# kill -9 [pid]
一般推荐使用前面两种,因为kill强杀进程,可能会导致数据损坏,如果损坏则需手动修复:
# 先删除数据目录下的所有锁文件
[root@~]# rm -rf /soft/mongodb/data/standalone/*.lock
# 再通过启动项对数据目录进行修复
[root@~]# /soft/mongodb/bin/mongod --repair --dbpath=/soft/mongodb/data/standalone
❽ 单纯的命令行不便于操作,所以通常会使用可视化工具来操作,而MongoDB官方提供了一个可视化工具:MongoDB Compass,可以先点击>>官网下载地址<<,直接下载解压即用的ZIP包。
当然,其实官方这款工具并不算好用,如果你有Navicat Premium(黄色图标那款),可以直接通过Navicat来连接MongoDB操作。
❾ 为了外部可以连接,需要开放MongoDB端口、更新防火墙(关闭防火墙也行):
[root@~]# firewall-cmd --zone=public --add-port=27017/tcp --permanent
[root@~]# firewall-cmd --reload
[root@~]# firewall-cmd --zone=public --list-ports
开放端口后,就可以通过可视化工具来连接操作了(如果你通过Navicat工具连接,是看不到三个默认库的)。
1.2、MongoDB增删改查
搭建好MongoDB的环境后,接着学习一下最基本的CRUD操作,首先声明: MongoDB中的多数操作都带有隐式创建特性 ,啥意思呢?好比你使用一个数据库,如果没有则会自动创建;使用一个集合时,没有也会自动创建……
这里咱们先创建一个数据库和集合,如下:
// 切换到zhuzi库,没有会自动创建
use zhuzi;
// 向xiong_mao集合插入一条数据(没有集合会自动创建)
db.xiong_mao.insert({_id:1});
和Python一样,最后的分号可写可不写,不过建议写上,以此增加代码的可读性。
现在继续往xiong_mao集合中插入两条数据:
db.xiong_mao.insert({_id:2, name:"肥肥", age:3, hobby:"竹子"});
db.xiong_mao.insert({name:"花花", color:"黑白色"});
此时大家会发现,这两条数据同样可以插入成功,前面咱们并没有像使用MySQL一样,先定义好表结构!从这里就印证了一开始所说的“无模式”特点,接着学学查询:
// 查询xiong_mao集合的所有数据
db.xiong_mao.find();
// ------- 返回结果 ----------
[
{_id:1},
{_id:2,name:'肥肥',age:3,hobby:'竹子'},
{
_id:ObjectId("64d0b843fa3b00006f0044d6"),
name:'花花',
color:'黑白色'
}
]
注意观察第三条数据,在插入时我们并未指定_id值,可为啥还是有这个字段呢?因为_id是mongoDB的默认字段,每个文档(每行数据)必须要有该字段,如果插入时未指定该字段,会自动生成一个类似于雪花ID的ObjectId值,mongoDB会使用_id来维护数据的存储结构(类似于InnoDB的隐藏列-row_id,后面再细聊)。
如何根据指定条件查询数据呢?如下:
// 查询_id=2的数据
db.xiong_mao.find({_id:2});
// 查询name=花花的数据
db.xiong_mao.find({name:"花花"});
大家会发现,前面我们以Json形式将数据插入到集合后,在查询时,咱们可以直接通过Json中的字段名来操作,这也就印证了最开始所说的“半结构化”特征,因为像Redis、Memcached这类NoSQL,虽然也能把数据Json序列化后存进去,但想要操作时,只能先读出来再反序列化成对象,不能直接对序列化后的Json字符串进行操作!
最后再来学习一下修改、删除操作:
// 将_id=2的数据,爱好修改为:吃竹子、睡觉
db.xiong_mao.update({_id:2},{hobby:"吃竹子、睡觉"});
// 上面那种方式,会导致其他字段变null,要记得加{$set:},表示局部修改
db.xiong_mao.update({_id:2},{$set:{hobby:"吃竹子、睡觉"}});
// 删除_id=1的数据
db.xiong_mao.remove({_id:1});
OK,我们过了一下最简单的CRUD操作,这里主要是让大家先熟悉下语法,诸位也可以自行多练习一下。
相较于SQL的语法来说,MongoDB的语法显得有点反人类;反观同为NoSQL的Redis,它的命令则显得简洁清爽许多。当然,熟悉JS的小伙伴,接触这个语法不算太难,毕竟这就是JS的语法,如果只是纯后端的开发者,想适应过来需要一定的练习。
1.3、库与集合的命令
熟悉了基本的CRUD语法后,进阶一点的语法咱们放到后面慢慢学,这里先熟悉下常用的库、集合的命令:
• 查询所有数据库:show dbs;或show databases;
• 切换/创建数据库:use 库名;
• 查看目前所在的数据库:db;
• 查看MongoDB目前的连接信息:db.currentOp();
• 查看当前数据库的统计信息:db.stats();
• 删除数据库:db.dropDatabase("库名");
• 查看库中的所有集合:show collections;或show tables;
• 显式创建集合:db.createCollection("集合名");
• 查看集合统计信息:db.集合名.stats();
• 查看集合的数据大小:db.集合名.totalSize();
• 删除指定集合:db.集合名.drop();
上述这些管理数据库、集合的命令只需简单了解,毕竟大多情况下,都可以通过可视化工具来完成这些操作,所以下面开始学习MongoDB中的文档操作命令。
二、MongoDB渐悉
下次再次从CRUD操作开始,对MongoDB的命令建立全面认知,先来看看新增/插入操作。
2.1、新增操作
MongoDB中提供了三个显式向集合插入数据的方法:
/ 向集合插入单条或多条数据(需要用[]来包裹多个文档)
db.xiong_mao.insert([
{_id:4,name:"黑熊",age:3,food:{name:"黄金竹",grade:"S"}},
{_id:5,name:"白熊",age:4,food:{name:"翠绿竹",grade:"B"}}
]);
// 向集合插入单条数据
db.xiong_mao.insertOne({_id:6,name:"棕熊"});
// 向集合批量插入多条数据
db.xiong_mao.insertMany([
{_id:7,name:"红熊",age:2,food:{name:"白玉竹",grade:"S"}},
{_id:8,name:"粉熊",age:6,food:{name:"翡翠竹",grade:"A"}}
]);
从案例中可发现,每个字段可以无限嵌套json。同时,这三个insert方法都有两个可选项,如下:
db.collection.insertXXX(
[<document 1>,<document 2>,...],
{
writeConcern:<document>,
ordered:<boolean>
}
)
writeConcern表示嵌套文档,这个咱们后续再细说;ordered表示本次是否按顺序插入,2.6以上版本默认为true,表示按指定的顺序插入数据。
除开上面三个常用的插入方法外,MongoDB还可以通过其他方式实现数据新增,如:
const bulkOps =[
{insertOne:{document:{_id:9,name:"黄熊"}}},
{insertOne:{document:{_id:10,name:"灰熊"}}}
];
db.xiong_mao.bulkWrite(bulkOps);
bulkWrite()方法可以传入一个操作数组,MongoDB会按照给定的操作顺序依次执行,其中还可以放修改、删除等MongoDB支持的操作。最后,还能通过修改命令,向集合中隐式插入数据,在使用修改命令时,将upsert设为true即可(后面会演示)。
2.2、删除操作
MongoDB中的删除命令,有remove、delete两类方法:
// 根据指定条件删除集合中的数据
db.xiong_mao.remove({_id:1});
// 删除集合中的所有数据(不写条件即可)
db.xiong_mao.remove({});
// 根据条件删除单条数据(有多条数据满足条件时,只会删第一条)
db.xiong_mao.deleteOne({_id:6, name:"棕熊"});
// 根据条件删除多条数据(满足条件的全部删除)
db.xiong_mao.deleteMany({name:"红熊"});
// 根据条件删除满足条件的第一条数据,并返回删除后的数据
db.xiong_mao.findOneAndDelete({_id:2});
当然,这里只列出了根据等值条件删除的操作,类似于SQL中的<、>、in、or、and……怎么写呢?这些放到后续的查询操作中讲解,因为条件过滤器在MongoDB中是通用的。
2.3、修改操作
想要更新一个集合中的数据时,可以使用update、replace操作:
// 根据条件修改集合中的单条数据(多条数据满足条件时,只修改第一条)
db.xiong_mao.updateOne({_id:7},{$set:{name:"英熊"}});
// 根据条件修改集合中的多条数据(color字段不存在时,自动创建并赋值)
db.xiong_mao.updateMany({age:3},{$set:{color:"黑白色"}});
// 根据条件替换掉单行数据(使用新数据替换老的数据)
db.xiong_mao.replaceOne({_id:6},{name:"棕熊",age:3,color:"棕色"});
// 根据条件修改集合中的单条数据(可以通过.分割的形式,修改嵌套的json)
db.xiong_mao.update({_id:8},{$set:{age:3,"food.grade":"C"}});
// 根据条件修改集合中的单/多条数据(如果想通过update更新多条,需要使用multi)
db.xiong_mao.update({age:3},{$set:{hobby:"竹子"}},{multi:true});
修改操作默认是全量修改,即使用指定的值,覆盖原有的整条数据,如果有些字段值在修改时未给定,则会变为null(消失)。为此,如若只想修改某几个字段,记得在前面加上$set选项。
当然,这里也仅是用_id在做等值条件修改,后面讲完查询操作后,大家可以自行套入各种复杂条件进行修改。
还记得提过的“修改时隐式新增”嘛?演示一下:
db.xiong_mao.update(
{_id:11},
{name:"紫熊", age:3, food:{name:"明月竹", grade:"A"}},
{upsert:true}
);
在修改时,只需指定upsert:true即可,这样在未匹配到对应条件的数据时,会将本次修改的数据插入到集合中,而前面演示的所有修改方法,都支持指定upsert选项。
修改操作除开上述方法外,还可以通过findAndModify()、findOneAndUpdate()、findOneAndReplace()方法来修改,如:
db.xiong_mao.findAndModify({
query:{_id:8},
update:{$set:{color: "紫色"}},
new: true
});
这些findAnd开头的修改方法,会根据条件修改满足条件的第一条数据,修改完之后,如果new指定为true,则会返回修改后的数据,如果为false,则返回修改前的数据(其余两个方法类似,不再继续演示)。
2.4、查询操作
增删改查的前三项过完了,接着来说说查询操作,这应该属于最复杂的一项,咱们一点点开始接触。
2.4.1、基本查询语句
// 查询集合所有数据
db.xiong_mao.find();
// 根据单个等值条件查询数据
db.xiong_mao.find({_id:2});
// 查询满足多个等值条件的数据(and查询)
db.xiong_mao.find({age:3,"food.grade":"S"});
// 查询满足任意一个条件的数据(or查询)
db.xiong_mao.find({$or:[{age:2},{"food.grade":"S"}]});
// 查询单字段满足任意一个条件的数据(in查询)
db.xiong_mao.find({age:{$in:[2,4]}});
// 查询颜色为黑白色,并且年龄小于5岁的数据
db.xiong_mao.find({color:"黑白色",age:{$lt:5}});
// 查询爱好为竹子,或id大于9的数据
db.xiong_mao.find({$or:[{hobby:"竹子"},{_id:{$gt:9}}]});
// 查询id小于等于5,并且(age大于等于2 或 name为肥肥)的数据
db.xiong_mao.find({
_id:{$lte:5},
$or:[{age:{$gte:2}},{name:"肥肥"}]
});
// 查询name不为“白熊” 或 age 不大于 2 的数据
db.xiong_mao.find({$nor:[{name:"白熊"},{age:{$gt:2}}]});
// 查询id在3~5之间的数据(between and范围查询)
db.xiong_mao.find({$and:[{_id:{$gte:3}},{_id:{$lte:5}}]});
// 查询name以“粉”开头的数据(like右模糊查询)
db.xiong_mao.find({name:/^粉/});
上述一些查询语句,对应着SQL中的基本查询,如=、<、>、<=、>=、in、like、and、or,大家仔细观察会发现,其中有许多$开头的东东,这个是啥?在MongoDB中称之为操作符,操作符有许多,分别对应着SQL中的关键字与特殊字符,下面列写常用的:
| SQL | MongoDB |
|---|---|
= | : |
=、<、>、<=、>=、!= | $eq、$lt、$gt、$lte、$gte、$ne |
in、not in | $in、$nin |
and、or、not、is null | $and、$or、$not、$exists |
+、-、*、/、% | $add、$subtract、$multiply、$divide、$mod |
group by、order by | $group、$sort |
... | ... |
上表仅仅只列出了一些在SQL中比较常见的,实则MongoDB提供了几百个操作符,以此来满足各类场景下的需求,如果你想要详细了解,可以参考MongoDB官网-Operators,当然,如果你英语阅读能力欠佳,可以参考MongoDB中文网-运算符。
接着来看看其他查询的语法:
// 对指定字段去重,并返回去重后的字段值列表
db.xiong_mao.distinct("age");
// 根据条件统计集合内的数据行数
db.xiong_mao.count({age:3});
// 根据条件进行分页查询(limit写行数,skip写跳过前面多少条)
db.xiong_mao.find({_id:{$lt:6}}).skip(0).limit(2);// 第一页
db.xiong_mao.find({_id:{$lt:6}}).skip(2).limit(2);// 第二页
// 根据指定字段进行排序查询(order by查询)
// 根据年龄升序,年龄相同根据id降序(1:升序,-1:降序)
db.xiong_mao.find().sort({age:1,_id:-1});
// 投影查询:只返回指定的字段(0表示不返回,1代表返回)
db.xiong_mao.find({color:"黑白色"},{_id:0,name:1,color:1});
这里又列出了一些SQL中经常执行的操作,如统计、去重、排序、分页、投影查询等,和SQL一样,不同类型的函数,执行的优先级不一样,例如:
db.xiong_mao.find({_id:{$lt:6}}).limit(2).skip(2).sort({_id:-1}).count();
这条查询语句中,包含了limilt()、skip()、sort()、count()四个方法,可实际的执行顺序,跟书写的顺序无关,这些方法同时存在时,执行的优先级为:sort() > skip() > limilt() > count()。
2.4.2、聚合管道查询
好了,如果你想要实现更复杂的查询操作,则可以通过MongoDB提供的聚合管道来完成,语法如下:
db.collection.aggregate(
pipeline:[<stage>,<...>],
options:{
explain:<boolean>,
allowDiskUse:<boolean>,
cursor:<document>,
maxTimeMS:<int>,
bypassDocumentValidation:<boolean>,
readConcern:<document>,
collation:<document>,
hint:<stringor document>,
comment:<any>,
writeConcern:<document>,
let:<document>// Added in MongoDB 5.0
}
);
聚合管道方法接收两个入参,第一个是数组型的聚合操作,第二个是可选项,先解释下常用的选项:
• explain:传true表示返回聚合管道的详细执行计划;
• allowDiskUse:是否允许使用硬盘进行聚合操作,内存不足时使用磁盘临时文件进行计算;
• maxTimeMS:指定聚合操作的最大执行时间(单位ms),超时会被强制终止;
• hint:显式指定使用那些索引进行聚合操作;
简单了解几个常用选项后,我们来重点关注一下pipeline参数,使用方式如下:
db.collection.aggregate([
// 阶段1
{$stage1:{/* 阶段1的操作 */}},
// 阶段2
{$stage2:{/* 阶段2的操作 */}},
// ...
]);
观察上述语法,首先咱们需要指定操作符,这是为了声明当前阶段的类型,例如$group,接着可以指定每个阶段具体要做的事情。同时,聚合管道中的每个阶段,都会将上一阶段输出的数据,视为当前阶段输入的数据,和Stream流类似,下面上些例子理解,如下:
/* 按年龄进行分组,并统计各组的数量(没有age字段的数据统计到一组) */
db.xiong_mao.aggregate([
// 1:通过$group基于age分组,通过$sum实现对各组+1的操作
{$group:{_id:"$age",count:{$sum:1}}},
// 2:基于前面的_id(原age字段)进行排序,1代表正序
{$sort:{_id:1}}
]);
/* 按年龄进行分组,并得出每组最大的_id值 */
db.xiong_mao.aggregate([
// 1:先基于age字段分组,并通过$max得到最大的id,存到max_id字段中
{$group:{_id:"$age",max_id:{$max:"$_id"}}},
// 2:按照前面的_id(原age字段)进行排序,-1代表倒序
{$sort:{_id:-1}}
]);
/* 过滤掉食物为空的数据,并按食物等级分组,返回每组_id最大的熊猫姓名 */
db.xiong_mao.aggregate([
// 1:通过$match操作符过滤food不存在的数据
{$match:{food:{$exists:true}}},
// 2:通过$sort操作符,基于_id字段进行倒排序
{$sort:{_id:-1}},
// 3:通过$group基于食物等级分组,并通过$max得到_id最大的数据,
// 并通过$first拿到分组后第一条数据(_id最大)的name值
{$group:{_id:"$food.grade",max_id:{$max:"$_id"},name:{$first:"$name"}}},
// 4:最后通过$project操作符,只显示_id(原food.grade)、name字段
{$project:{_id:"$_id",name:1}}
]);
上面举了三个简单的聚合操作例子,但相信对于绝大多数刚接触的小伙伴来说,这些语句看起来十分头大,一眼望过去全都是符号+符号,这是因为MongoDB中,使用操作符代替了SQL中的函数与关键字,所以越是复杂的场景,使用到的操作符越多,对传统型的SQL Boy来说,可读性会越差~
这里为了便于大家理解,先列出MongoDB聚合管道操作符和SQL聚合关键字/函数的对比:
| SQL关键字/函数 | MongoDB聚合操作符 |
|---|---|
where、having | $match |
group by | $group |
order by | $sort |
select field1、field2… | $project |
limit | $limit、$skip |
sum()、count()、avg()、max()、min() | $sum、$sum:1、$avg、$max、$min |
join | $lookup |
当然,上面列出的仅是沧海一粟,MongoDB的聚合管道中可用的操作符有几百个,不管是SQL中有的,还是没有的功能/函数,都能找到对应的操作符代替,具体大家可以参考MongoDB官网-Aggregation Pipeline Operators,或MongoDB中文网-聚合管道操作符。
话归正题,咱们来稍微解读一下前面写出的聚合管道查询语句,先拿最简单的第一条来说:
/* 按年龄进行分组,并统计各组的数量 */
db.xiong_mao.aggregate([
{$group: {_id:"$age", count: {$sum:1}}},
{$sort: {_id:1}}
]);
在第一阶段中,使用$group操作符来完成分组动作,其中_id并不是原数据中的_id,而是代表想聚合的数据主键,上面的需求想基于年龄分组,所以_id设置为$age即可。
注意:在聚合查询中,也会使用来引用原数据中的字段,案例中的`age并不是一个操作符,而是获取原数据的age字段,这种方式也可以用来拿其他字段,如name`、`color……`。
在第一阶段中,咱们还定义了一个count字段,这相当于SQL中的别名,该字段的值,则是由{$sum:1}统计得出的,这段逻辑相当于:
Map<Integer,Integer> groupMap =newHashMap<>();
for(XiongMao xm : xiongMaoList){
Integerage= xm.getAge();
if(groupMap.get(age)==null){
groupMap.put(age,1);
}else{
Integercount= groupMap.get(age)+1;
groupMap.put(age, count);
}
}
第一阶段的分组统计工作完成后,接着会来到第二阶段,其中使用了$sort操作符,对_id字段进行了升序排序,不过这里要注意,因为第二阶段输入的数据,是第一阶段输出的数据,所以第二阶段的_id,实际上是原本的age字段,这意味着在对年龄做升序排序!
OK,相信经过这番解释后,大家对MongoDB的聚合管道操作有了一定理解,那接着继续看些案例加深印象(也可以尝试着自己练习练习):
/* 多字段分组:按食物等级、颜色字段分组,并求出每组的年龄总和 */
db.xiong_mao.aggregate([
// 1:_id中写多个字段,代表按多字段分组,接着通过$sum求和age字段
{$group:{_id:{grade:"$food.grade",color:"$color"},total_age:{$sum:"$age"}}}
]);
/* 分组后过滤:根据年龄分组,然后过滤掉数量小于3的组 */
db.xiong_mao.aggregate([
// 1:先按年龄进行分组,并通过$sum:1对每组数量进行统计
{$group:{_id:"$age",count:{$sum:1}}},
// 2:通过$match操作符,保留数量>3的分组(过滤掉<3的分组)
{$match:{count:{$gt:3}}}
]);
/* 分组计算:根据颜色分组,求出每组的数量、最大/最小/平均年龄、所有姓名、首/尾的姓名 */
db.xiong_mao.aggregate([
// 1:按颜色分组
{$group:{_id:"$color",
// 计算每组数量
count:{$sum:1},
// 计算每组最大年龄
max_age:{$max:"$age"},
// 计算每组最小年龄
min_age:{$min:"$age"},
// 计算每组平均年龄
avg_age:{$avg:"$age"},
// 通过$push把每组的姓名放入到集合中
names:{$push:"$name"},
// 获取每组第一个熊猫的姓名
first_name:{$first:"$name"},
// 获取每组最后一个熊猫的姓名
last_name:{$last:"$name"}}}
]);
/* 分组后保留原数据,并基于原_id排序,然后跳过前3条数据,截取5条数据 */
db.xiong_mao.aggregate([
// 1:先基于color分组,并通过$$ROOT引用原数据,将其保存到数组中
{$group:{_id:"$color",xiong_mao_list:{$push:"$$ROOT"}}},
// 2:通过$unwind操作符,将xiong_mao_list数组分解成一条条数据
{$unwind:{path:'$xiong_mao_list',
// 使用index字段记录数组下标,preserveNullAndEmptyArrays可以保证不丢失数据
includeArrayIndex:"index",preserveNullAndEmptyArrays:true}},
// 3:基于分解后的_id字段进行排序,1代表升序
{$sort:{"xiong_mao_list._id":1}},
// 4:通过$skip跳过前3条数据
{$skip:3},
// 5:通过$limit获取5条数据
{$limit:5}
]);
/* 根据年龄进行判断,大于3岁显示成年、否则显示未成年(输出姓名、结果) */
db.xiong_mao.aggregate([
// 1:通过$project操作符来完成投影输出
{$project:{
// 不显示_id字段,将name字段重命名为:“姓名”
_id:0,姓名:"$name",
// 通过$cond实现逻辑运算,如果年龄>=3,显示成年,否则显示未成年
result:{
$cond:{
if:{$gte:["$age",3]},
then:"成年",
else:"未成年"
}}}}
]);
好了,关于聚合管道的案例,暂时就写到这里,想要学习其他操作符的使用,可以参考之前给出的官网链接。这里主要说明几点要素。
首先聚合管道的每个阶段,内存限制一般为100MB,如果超出这个限制,执行时会报错,因此当需要处理大型数据集时,记得把allowDiskUse选项置为true,允许MongoDB使用磁盘临时文件来完成计算。
其次呢,使用聚合管道时也要牢记,筛选、过滤类型的阶段,最好放到前面完成,这样有两个好处:一是可以快速将不需要的文档过滤掉,减少管道后续阶段的工作量;二是如果在$project、$group这类操作前执行$match,$match阶段可以使用索引,因为此时属于在操作原本的文档,索引自然不会失效,可如果放到$project、$group……后面再执行,原数据被改变后,前面的阶段会形成新的文档,并输出到$match阶段中,这时索引不一定能继续生效。
最后,按官网所说,除了$out、$merge和$geoNear这些阶段外,其他类型的所有阶段,都可以在管道中出现多次,这意味着MongoDB会比传统型SQL更强大,比如可以多次分组、筛选……,结合管道里的几百个操作符,你可以实现各种复杂场景下的聚合操作。
2.4.3、嵌套文档的增删改查
在关系型数据库中,我们可以通过树表、主子表等思想,抽象出各种结构以满足业务需求,举个例子理解,比如下单业务中,用户一笔订单可能会包含多个商品,所以会用主子表的思想,对订单数据进行存储,订单数据存到主表中、订单详情数据放到子表,两表之间通过主外键关联,后续可以通过join来查询、使用。
但由于MongoDB是无模式、半结构化的存储方式,因此无法像传统型数据库那样,通过主外键来关联不同表(集合),毕竟一个集合没有明确的字段定义,可以随意插入不同字段。那MongoDB又该如何满足树表、主子表这种业务的存储需求呢?答案是通过文档嵌套来代替!
在前面学习insert操作时,大家不难得知:MongoDB集合中的每个字段,可以继续嵌套Json对象,因为MongoDB本身就是以Json格式存储数据,所以只要是能用Json格式表达出来的数据,都可以放到集合中存储,比如:
db.xiong_mao.insert([
{_id:12, name:"金熊", age:4, hobby:["吃饭","睡觉"], food:{name:"黄金竹", grade:"S"}}
]);
在插入数据时,字段的值可以放入普通类型,也可以放入数组、另一个Json对象,所以早期的MongoDB,推荐通过嵌入文档,来代替SQL中的join多表连接查询,前面举例提到的订单、订单详情这种一对多的主子关系,可以用如下方式代替:
/* 以下数据仅为示例,不要纠结订单数据的不完整性 */
db.order.insert([{
_id:1,
order_number:"x-20230811185422",
order_status:"已付款",
pay_fee:888.88,
pay_type:"他人代付",
order_user_id:"2222222",
pay_user_id:"11111111",
pay_time:newDate(),
order_details:[
{order_detail_id:1,shop_id:6,shop_price:666.66,status:"待发货"},
{order_detail_id:2,shop_id:2,shop_price:222.22,status:"待发货"}
]
}]);
这样,当需要查询一笔订单的详情记录时,就直接查询oder集合即可,因为订单详情数据存储在order_details字段中,这个是一个数组,每个数组的元素则是一条条Json格式的订单详情。
下面来聊聊嵌套文档的增删改查,这里跟操作普通文档有些许出入,如下:
/* 新增单条订单详情:通过order集合的update方法来实现 */
db.order.update(
// 修改条件:修改_id=1的订单数据
{_id:1},
// 通过$push操作符,往order_details中压入一条新记录
{$push:{
order_details:{
order_detail_id:3,
shop_id:4,
shop_price:444.44,
status:"待发货"
}
}}
);
/* 新增多条订单详情记录 */
db.order.update(
{_id:1},
{$push:{
order_details:{
// 这里使用$each操作符,声明本次要push多个元素
$each:[
{order_detail_id:4,shop_id:3,shop_price:333.33,status:"待发货"},
{order_detail_id:5,shop_id:1,shop_price:111.11,status:"待发货"}
]
}
}}
);
/* 删除满足条件的订单详情数据 */
db.order.update(
{_id:1},
// 通过$pull操作符,将order_details满足条件的数据弹出
{$pull:{
// 删除order_detail_id大于3的订单详情数据
order_details:{order_detail_id:{$gt:3}}
}
});
/* 修改单条满足条件的订单详情数据 */
db.order.update(
// 这里给定了两个条件,订单ID=1,并且订单详情ID=1
{_id:1,"order_details.order_detail_id":1},
// 通过$set操作符,来对集合中的文档进行局部修改
{$set:{
// 将状态改为已发货,这里的$,表示数组中的当前元素,即条件匹配的数组元素
"order_details.$.status":"已发货"
}}
);
/* 修改多条满足条件的订单详情数据 */
db.order.update(
// 先查询到订单ID=1的数据
{_id:1},
{$set:{
// 这里使用的是$[elem]占位符,代表着要更新的元素
"order_details.$[elem].status":"已发货"
}},
// 这里定义了一个数组过滤器,会把满足条件的订单详情记录筛选出来
{arrayFilters:[
// 这里的elem代表数组中的元素,过滤条件为:订单详情ID=2、3的数据
{"elem.order_detail_id":{$in:[2,3]}}
]}
);
/* 修改满足多个条件的单条数据 */
db.order.update(
{
// 这里是基于order_details字段在做条件过滤,可以跨文档(在不同数据行中筛选)
order_details:{
// $elemMatch操作符代表匹配多个条件
$elemMatch:{
status:"已发货",
shop_id:2
}}
},
// 对满足多个条件的单条数据进行修改(要修改多条,参考上个案例的用法即可)
{$set:{
"order_details.$.status":"已签收"
}}
);
/* 查询符合条件的单条数据 */
db.order.find(
// 查询order_detail_id==1的订单详情数据
{"order_details.order_detail_id":1},
// 限制返回的字段,不返回_id,order_details.$表示只返回满足条件的订单详情数据
{"_id":0,"order_details.$":1}
);
/* 查询满足多个条件的多条数据 */
db.order.aggregate([
// 使用$project操作符完成投影查询
{$project:{
// 不返回_id字段
_id:0,
// 只返回order_details字段
order_details:{
// 通过$filter操作符,实现按条件过滤数据
$filter:{
// 这里相当于for循环,$order_details是要遍历的数组,$detail是别名
input:"$order_details",
as:"detail",
// 这里是过滤的条件,$and表示两个条件都需要满足
cond:{
$and:[
// 返回order_detail_id>=1 && status为“已签收”的数据
{$gte:["$$detail.order_detail_id",1]},
{$eq:["$$detail.status","已签收"]}
]
}
}
}}}
]);
好了,上面把嵌套文档的增删改查操作简单过了一遍,其实嵌入式文档的CRUD,都依赖于外部集合的CRUD方法完成,唯一有区别的地方就在于:我们需要结合$push、$pull、$elemMatch、$[elem]等各种数组操作符,来实现嵌入式文档的增删改查。不过如若只嵌入了一个文档,而不是一个文档数组时,操作的方法有有些不同,如下:
// 以之前xiong_mao集合中,id=1的这条数据为例
db.xiong_mao.insert({_id:1,name:"肥肥",age:3,hobby:"竹子"});
// 为其添加一个内嵌文档
db.xiong_mao.update(
{_id:1},
{$set:{food:{name:"帝王竹",grade:"A"}}},
{upsert:true}
);
// 查询一次看看这条数据(此时可以看到内嵌文档已经被添加)
db.xiong_mao.find({_id:1});
{
_id:1,
name:'肥肥',
age:3,
hobby:'竹子',
color:'黑白色',
food:{name:'帝王竹',grade:'A'}
}
// 修改内嵌文档中的某个字段值
db.xiong_mao.updateMany(
{_id:1},
// 修改单个字段,要用 . 的形式
{$set:{"food.grade":"S"}},
{upsert:true}
);
// 删除内嵌文档中的单个字段
db.xiong_mao.update(
{_id:1},
// 通过$unset操作符,将对应字段置为空即可
{$unset:{"food.grade":""}},
{upsert:true}
);
// 删除整个内嵌文档
db.xiong_mao.update(
{_id:1},
// 将整个内嵌文档字段置为空即可
{$unset:{food:""}},
{upsert:true}
);
ok,关于文档嵌入的内容咱们先就此打住,来思考一个问题:真的所有带有主外键关系的结构,都可以通过文档嵌入代替吗?
这个答案明显是NO,为什么?就拿咱们前面“订单-订单详情”例子中的商品来说,每一笔订单详情记录,都需要跟商品产生绑定关系吧?这时我们总不能把整个商品的数据,全部嵌入到订单详情的某个字段中吧?因为一个商品可以被多次购买!如果真按这样存,假设一个商品单月销量10W+,产生的10W+订单详情记录,难道都把这个商品的完整数据嵌入一次吗?显然不合理。
正因如此,有些场景下,咱们无法通过文档嵌入来代替原本的多表关联,所以MongoDB在3.2版本以后,也支持了多个集合之间关联查询,就类似于SQL中的join一样!只不过功能没SQL强大,并且必须在聚合管道中使用,下面一起来看看。
2.4.4、多个集合关联查询
现在假设有商店shop_store、商品product两个集合,数据如下:
db.shop_store.insertMany([
{_id:1,name:"熊猫高级会所",address:"地球市天上人间街道888号",grade:"五星"},
{_id:2,name:"竹子商店",address:"地球市绿竹林街道666号",grade:"五星"}
]);
db.product.insertMany([
{_id:1,shop_store_id:1,name:"水",description:"能有效缓解口渴",price:2.00},
{_id:2,shop_store_id:2,name:"米饭",description:"能有效缓解饥饿",price:1.00},
{_id:3,shop_store_id:1,name:"香烟",description:"能有效缓解寂寞",price:88.88},
{_id:4,shop_store_id:1,name:"酒",description:"能有效缓解忧愁",price:99.00},
{_id:5,shop_store_id:1,name:"牛奶",description:"能帮助长身体",price:4.00},
{_id:6,shop_store_id:2,name:"咖啡",description:"能有效缓解疲劳",price:9.99},
{_id:7,shop_store_id:1,name:"棉衣",description:"能有效缓解寒冷",price:188.00},
{_id:8,shop_store_id:2,name:"辣条",description:"能有效缓解嘴馋",price:5.00}
]);
在以外,为了实现数据的关联性,我们会直接将商店数据,嵌入到商品数据的某个字段中,而在目前的这个例子中,却是通过shop_store_id字段来关联商品所在的商店,查询时又该如何处理呢?如下:
db.shop_store.aggregate([
{
$lookup:{
from:"product",
localField:"_id",
foreignField:"shop_store_id",
as:"products"
}
}
]);
在上述代码中,使用了聚合管道中的$lookup操作符,来实现多个集合之间的关联查询,其中主要有四个参数:
• from:要关联的集合名称,这里是用商店关联商品,所以写product;
• localField:shop_store集合中用于关联的字段,这里是_id;
• foreignField:product集合中用于关联的字段,这里是shop_store_id;
• as:指定两个集合匹配的数据,要保存到的字段名称,这里写了products。
由于关联查询,也依靠于聚合管道来完成,为此大家可以在关联查询的前后,插入各种业务所需的阶段,以满足各种特殊场景下的需求,不过这里注意:关联查询结束后,驱动集(调用aggregate方法的集合)的字段会完整输出,而被驱动集的字段,会以Json对象的形式,放入到指定的字段中,最终形成一个Json数组,即案例中的products。
最后,如果你的需求中,需要关联并筛选数据,那么最好将筛选动作放到关联查询前面,尽可能的减小关联查询时的数据集,因为$lookup操作符,底层就是两个for循环,如果两个集合都有100W条数据,未做筛选直接关联查询,此时性能堪忧……
三、MongoDB索引机制
任何数据库都有索引这一核心功能,MongoDB自然不例外,而且MongoDB在索引方面特别完善,毕竟作为数据库领域的后起之秀,它集百家之长,将“借鉴”这一思想发挥到了极致,先来看看MongoDB索引的概念词:
单列索引、组合索引、唯一索引、全文索引、哈希索引、空间(地理位置)索引、稀疏索引、TTL索引……
怎么样?相信看过MySQL索引这篇文章的小伙伴一定眼熟,其中的索引名词和MySQL十分相似,接下来咱们挨个接触一下,当然,这里也先给出官方文档地址:MongoDB索引机制。
PS:早版本的MongoDB中,索引底层默认使用B-Tree结构,而4.x版本后,MongoDB推出了V2版索引,默认使用变种B+Tree来作为索引的数据结构(和MySQL索引的数据结构相同)。
3.1、初识MongoDB索引
在之前提到过,MongoDB会为每个集合生成一个默认的_id字段,该字段在每个文档中必须存在,可以手动赋值,如果不赋值则会默认生成一个ObjectId,该字段则是集合的主键,MongoDB会基于该字段创建一个默认的主键索引,后续基于_id字段查询数据时,会走索引来提升查询效率。
但当咱们基于其他字段查询时,由于未使用_id作为条件,这会导致find语句走全表查询,即从第一条数据开始,遍历完整个集合,从而检索到目标数据。当集合中的数据量,达到百万、千万、甚至更高时,意味着效率会直线下滑,在这种情况下,必须得由我们手动为频繁作为查询条件的字段建立索引。
这里咱们先来说说索引的分类,同MySQL一样,站在不同维度上来说,可以衍生出不同的分类。
从字段数量的维度划分:
• 单列索引:基于一个字段建立的索引;
• 组合索引:也叫复合索引、多列索引、联合索引,是由多个字段组成的索引;
• 多键索引:和上面的不同,如果索引字段为数组类型,MongoDB会专门为每个元素生成索引条目;
• 部分索引:使用一个或多个字段的前N个字节创建出的索引;
从排序维度上划分:
• 升序索引:一或多个字段组成的索引,排序方式完全为升序(从小到大);
• 降序索引:一或多个字段组成的索引,排序方式完全为降序(从大到小);
• 多序索引:多个字段组成的索引,但其中一部分字段为升序,一部分字段为降序;
从功能维度划分:
• 主键索引:MongoDB中默认为_id字段且不能更改,用于维护聚簇索引树;
• 普通索引:一或多个字段组成的索引,没有任何特殊性,只为提升检索效率;
• 唯一索引:一或多个字段组成的索引,值不能重复,且只允许一个文档不插入索引字段;
• 全文索引:一或多个字段组成的索引,集合内只能有一个,可以基于索引字段进行全文检索;
• 空间索引:基于地理空间数据字段创建的索引,支持平面几何的2D索引和球形几何的2D sphere索引;
从索引性质维度划分:
• 稀疏索引:结合唯一索引使用,允许一个唯一索引字段,出现多个null值;
• TTL索引:类似于Redis的过期时间,为一个字段创建TTL索引后,超时会自动删除整个文档;
• 隐藏索引:在不删除索引的情况下,把索引隐藏起来,语句执行时不再走索引,相当于关闭索引;
• 通配符索引:给内嵌文档、且会发生动态变化的字段创建的索引;
从存储方式维度划分:
• 聚簇索引:索引数据和文档数据存储在一起的索引;
• 非聚簇索引:索引数据和文档数据分开存储的索引;
从数据结构维度划分:
• B+树索引:索引底层采用B+Tree结构存储;
• 哈希索引:索引底层采用Hash结构存储;
显而易见,这里又出现了一堆索引相关的名词,不过好在其中大部分概念,和MySQL索引的概念相同,下面展开聊聊。
3.2、MongoDB索引详解
先来看看MongoDB中创建索引的命令,如下:
db.collection.createIndex(<key and index type specification>, <options>);
前面提到的所有索引,都是通过这一个方法创建,不同类型的索引,通过里面的参数和选项来区分,下面说明一下参数和可选项。
第一个参数主要是传字段,以及索引类型,这里可以传一或多个字段,用于表示单列/复合索引。
第二个参数表示可选项,如下:
• background:是否以后台形式创建索引,因为创建索引会导致其他操作阻塞;
• unique:是否创建成唯一索引;
• name:指定索引的名称;
• sparse:是否对集合中不存在的索引字段的文档不启用索引;
• expireAfterSeconds:指定存活时间,超时后会自动删除文档;
• v:指定索引的版本号;
• weights:指定索引的权重值,权值范围是1~99999,当一条语句命中多个索引时,会根据该值来选择;
接着还是以之前的xiong_mao集合为例,来阐述索引相关内容,数据如下:
db.xiong_mao.insert([
{_id:1,name:"肥肥",age:3,hobby:"竹子",color:"黑白色"},
{_id:2,name:"花花",color:"黑白色"},
{_id:4,name:"黑熊",age:3,food:{name:"黄金竹",grade:"S"}},
{_id:5,name:"白熊",age:4,food:{name:"翠绿竹",grade:"B"}},
{_id:6,name:"棕熊",age:3,food:{name:"明月竹",grade:"A"}},
{_id:7,name:"红熊",age:2,food:{name:"白玉竹",grade:"S"}},
{_id:8,name:"粉熊",age:6,food:{name:"翡翠竹",grade:"A"}},
{_id:9,name:"紫熊",age:3,food:{name:"烈日竹",grade:"S"}},
{_id:10,name:"金熊",age:6,food:{name:"黄金竹",grade:"S"}}
]);
3.2.1、单列索引
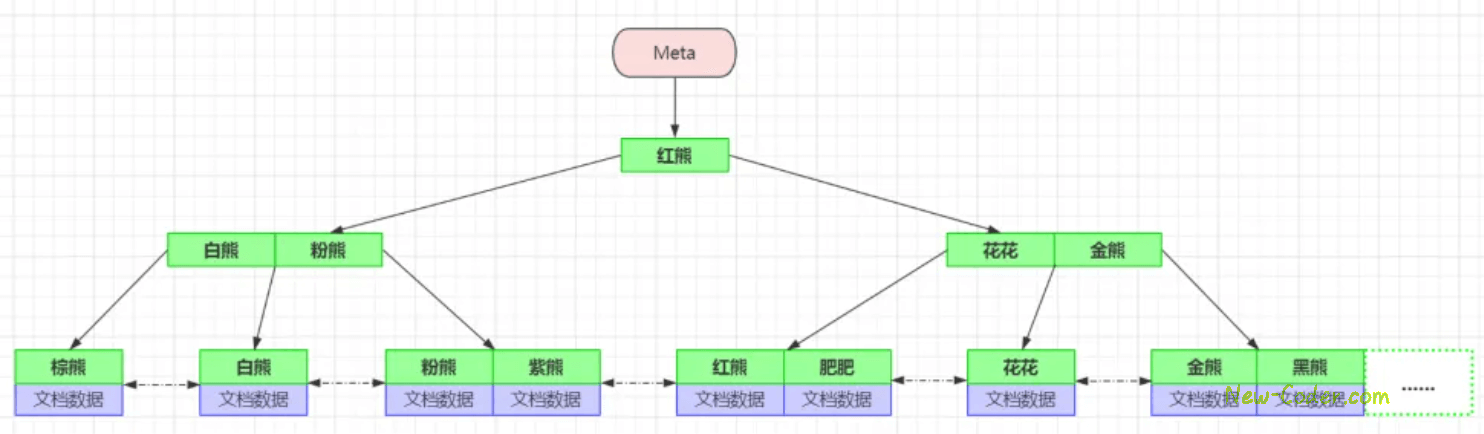
db.xiong_mao.createIndex({name: -1}, {name: "idx_name"});
这代表着基于name字段,创建一个名为idx_name的单列普通索引,-1代表降序,不过对于单字段的索引而言,排序方式并不重要,因为索引底层默认是B+Tree,每个文档之间会有双向指针,为此,MongoDB基于单字段索引查询时,既可以向前、也可以向后查找数据,示意图如下:
Mongodb索引
创建完成后,可以通过db.xiong_mao.getIndexes()命令查询索引,如下:
[
{v: 2, key: { _id: 1 }, name: '_id_'},
{v: 2, key: { name: -1 }, name: 'idx_name'}
]
这里可以看到,MongoDB默认给_id字段创建的索引,第二个则是咱们手动创建的索引,索引的版本为2(如果不指定索引名,会按“字段名+下划线+排序方式”规则默认生成)。
再来看一种情况,例如现在将集合中的爱好字段,变为一个数组:
{_id:1, name:"肥肥", age:3, hobby:["竹子", "睡觉"], color:"黑白色"}
现在给hobby字段创建一个索引,这时叫啥索引?多键索引!因为这里是基于单个数组类型的字段在建立索引,所以MongoDB会为数组中的每个元素,都生成索引的条目(即索引键),由于一个文档的数组字段,拥有多个元素,因此会创建多个索引键,这也是“多键索引”的名字由来。
3.2.2、复合索引
复合索引是指基于多个字段创建的索引,例如:
db.xiong_mao.createIndex({name:-1, age:1}, {name:"idx_name_age"});
这里基于name、age字段两个字段,创建了一个复合索引,其中指定了按name降序、age升序,这个排序就有意义了,MongoDB生成索引键时,会按照指定的顺序,来将索引键插入到树中。
说明:索引键=索引字段的值,比如现在一个文档的
name=zhuzi、age=3,索引键为zhuzi3。
注意:由于这里的顺序是{name:-1, age:1},所以当排序查询时,支持sort({name:-1,age:1})、sort({name:1,age:-1}),因为这两个顺序和树的组成顺序要么完全相同、相反,而当执行sort({name:-1,age:-1})、sort({name:1,age:1})排序查询时,将不会使用索引,因为这时和树的顺序冲突。
这里咱们用`explain这里咱们用explain命令浅浅分析一下:
命令浅浅分析一下:
db.xiong_mao.find({}).sort({name:1,age:1}).explain("executionStats");
db.xiong_mao.find({}).sort({name:-1,age:1}).explain("executionStats");
从图中能明显看出,第一条与索引顺序冲突的语句,走的是COLLSCAN全集合扫描;而第二条复合索引顺序的语句,走的是IXSCAN索引扫描,使用了name_-1_age_1这个索引检索到了数据,因此这点在使用复合索引时一定要注意!
同时,因为刚刚又给name、age字段建立了一个复合索引,所以最开始建立name单列索引,属于冗余的重复索引,这时可以通过dropIndex命令删除掉,如下:
// 自定义名称创建的索引,需要传入名称删除
db.xiong_mao.dropIndex("name_-1");
// 使用默认名称创建的索引,可以直接传入创建时的字段+顺序
db.xiong_mao.dropIndex({name:-1});
// 这个方法可以删除一个集合的所有索引(除开默认的_id索引外)
db.xiong_mao.dropIndexes();
顺便这里也提一句,如果索引在创建时未指定名称,中途是不可以重命名的,只能先删再建时重新命名。
3.2.3、唯一索引
唯一索引相信大家都熟悉,它必须创建在不会出现重复值的字段上,基于唯一索引查找数据时,找到第一个满足条件的数据,就会立马停止匹配,毕竟该字段的值在集合中是唯一的,创建的方式如下:
db.xiong_mao.createIndex({name:1}, {unique: true});
只需要将unique设置为true即可,现在再尝试向集合中插入一条name重复的文档:
db.xiong_mao.insertOne({name: "肥肥"});
[Error] index 0: 11000 - E11000 duplicate key error collection:
zhuzi.xiong_mao index: name_1 dup key: { name: "肥肥" }
这时就会因为name值违反唯一约束而报错。OK,再来看一个特殊情况:
db.xiong_mao.insertOne({_id:66, age: 1});
db.xiong_mao.insertOne({_id:77, age: 2});
这时大家查询一下该集合,会发现_id=66这条数据会插入进去,而77这条数据会报错,这是为什么?
因为MongoDB中,可以向集合中动态插入不同的字段,上面两条语句都没有指定name字段,这时MongoDB默认会将这两条语句的name字段置空,而name=null的情况,也会被当作一个索引键,插入到索引树中。由于name字段建立了唯一索引,因此空值情况也只能出现一次。
那这个问题能不能解决呢?当然可以,这里需要用到稀疏索引,“稀疏”是索引的一种特性,如下:
// 先删除索引
db.xiong_mao.dropIndex("name_1");
// 再重新建立一次,并将sparse选项置为true
db.xiong_mao.createIndex({name:1}, {unique:true, sparse:true});
这时再执行前面的两条语句,就能同时插入了!后续可以通过null值,来查询没有唯一索引字段的文档:
db.xiong_mao.find({name:null});
3.2.4、部分索引
部分索引即使用字段的一部分开创建索引,但必须要结合partialFilterExpression选项来实现,如下:
db.xiong_mao.createIndex(
// 给hobby字段创建索引
{hobby:1},
{partialFilterExpression:{
hobby:{
// 只为存在hobby字段的文档创建索引
$exists:true,
// 通过$substr操作符,截取前1个字节作为索引键
$expr:{$eq:[{$substr:["$hobby",0,1]},"prefix"]}
}
}
}
);
其实这就类似于MySQL中的前缀索引,不过MongoDB的中的部分索引功能更强大,还可以只为集合中的一部分文档创建索引,例如:
db.xiong_mao.createIndex(
{age: -1},
// 只为集合中年龄大于2岁的文档创建索引
{partialFilterExpression: {age: {$gt: 2}}}
);
为此,这里纠正一下:在最开始给出的索引分类概念中,将部分索引解释成了前缀索引的概念,实则不然,其实还可以为集合里的一部分数据创建索引!
3.2.5、TTL索引
TTL索引这个类型比较有趣,可以基于它实现过期自动删除的效果,主要依靠expireAfterSeconds选项来创建,不过只能在Date、ISODate类型的字段上,建立TTL索引,如下:
db.test_ttl.insertMany([
// new Date()表示插入当前时间
{_id:1,time:newDate()},
{_id:2,time:newDate()},
{_id:3,time:newDate()},
{_id:4,time:newDate()},
{_id:5,notes:"这条数据用于观察TTL删除特性"}
]);
db.test_ttl.find();
db.test_ttl.createIndex({time:1},{expireAfterSeconds:10});
上面新建了一个ttl_test集合,并向其中插入了5条数据,接着对time字段创建了一个TTL索引,给定的过期时间为10s,这里咱们稍等12s左右再去查询:
db.test_ttl.find();
[{_id: 5, notes: '这条数据用于观察TTL删除特性'}]
此时会发现,只剩下了_id=5这条没有time字段的数据,从这点就可以观察出TTL索引的特性,不过大家在使用时需要注意:TTL索引只能建在单字段上,不支持建立TTL复合索引;同时,TTL索引只能建立在类型为Date、ISODate的字段上,在其他类型的字段上建立TTL索引,文档永远不会过期。
这里说明一下,为什么TTL索引必须基于Date类型的字段创建呢?
因为MongoDB会使用该字段的值,作为计算的起始时间,如果在一个Date数组类型的字段上建立TTL索引,MongoDB会使用其中最早的时间来计算过期时间。
3.2.6、全文索引
在MySQL中想实现模糊查询,一般会采用like关键字;而在在MySQL中想实现模糊查询,一般会采用like关键字;而在MongoDB中想实现模糊查询,官方并没有提供相关方法与操作符,只能通过自己写正则的形式,实现模糊查找的功能,那有没有更好的方法呢?答案是有,为相应字段创建全文索引即可。
全文索引在之前讲MySQL索引时也聊到过,在数据量不大不小(几百万左右)、查询又不是特别复杂的情况下,直接上ElasticSearch、Solr等中间件,显得有点大材小用,此时全文索引就是这类搜索引擎的平替。不过相较于MySQL,MongoDB提供的全文索引,功能方面会更加强大。
创建的语法如下:
db.xiong_mao.createIndex({name: "text"}, {name:"ft_idx_name"});
这里对name字段建立了一个全文索引,和创建普通索引的区别在于:在字段后面加了一个text。
不过要注意,MongoDB全文索引停用词、词干和词器的规则,默认为英语,想要更改,这里涉及到创建索引时的两个可选项:
• default_language:指定全文索引停用词、词干和词器的规则,默认为english;
• language_override:指定全文索引语言覆盖的范围,默认为language;
不过注意,不管任何技术栈的全文索引,对中文的支持都不太友好,分词方面总会有点不完善,所以MongoDB很鸡贼,全文索引直接不支持中文,当你试图通过default_language:"chinese"去将语言改为中文时,会直接给你返回报错~
当然,正是由于MongoDB的全文索引不支持中文,因此就算你给一个字符串字段,建立了全文索引后,也无法实现全文搜索,如下:
db.xiong_mao.find({$text: {$search: "熊"}});
这段语句的含义是:通过全文索引搜索含“熊”这个关键字的数据,在咱们前面给出的集合数据中,name包含“熊”的数据有好几条,但这条语句执行之后的结果为null。想要解决这个问题,必须要手动安装第三方的中文分词插件,如mmseg、jieba等。
当然,如果你字段中的值是英文,这自然是支持的,例如:
// 先向集合中插入三个name为英文的文档
db.xiong_mao.insertMany([
{_id:21,name:"jack bear",age:1},
{_id:22,name:"coly bear",age:2},
{_id:23,name:"alan bear",age:3}
]);
// 再使用英文作为关键字进行全文搜索(多个关键字用空格分隔)
db.xiong_mao.find({$text:{$search:"jack coly"}});
// =============结果=============
[
{_id:22,name:'coly bear',age:2},
{_id:21,name:'jack bear',age:1}
]
结果很明显,全文索引对英文完全支持,不过关于全文索引更多的搜索方法,大家可自行查阅官方文档,或寻找相关资料,这里不再过多阐述。
3.2.7、空间索引
空间索引,这玩意儿很多人用不到,除非涉及到地图、出行类的业务,或者其他涉及到坐标的场景,毕竟这时才会存储经纬度,MongoDB的空间索引,必须建立在类型为Point的字段上,总共有三种空间索引:
• 2D:适用于平面上的二维几何数据;
• 2Dsphere:适用于球面上的二维几何数据;
• geoHaystack:2D索引的升级版,适用于平面的特定坐标数据(查询性能更高);
这里来演示一下,先创建一个名为“熊猫馆”的集合,并插入几条坐标数据:
db.panda_house.insertMany([
{_id:1,house_name:"熊猫高级会所",location:{type:"Point",coordinates:[-66.66,22.22]}},
{_id:2,house_name:"竹子高级会所",location:{type:"Point",coordinates:[-88.88,55.55]}},
{_id:3,house_name:"竹子爱熊猫会所",location:{type:"Point",coordinates:[-77.88,11.22]}}
]);
接着我们为其location字段,创建一个2dsphere空间索引:
db.panda_house.createIndex({location:"2dsphere"});
接着可以使用坐标来进行查询,例如查询某个坐标附近五公里内的熊猫馆:
db.panda_house.find(
// 基于location字段进行查询
{location:{
// $near用来实现坐标附近的数据检索,返回结果会按距离排序
$near:{
// $geometry操作符用于指定Geo对象(地理空间对象)
$geometry:{
type:"Point",coordinates:[-66.66,22.21]},
// $maxDistance限制了最大搜索距离为5000m(五公里)
$maxDistance:5000
}}
});
上述语句执行后,最终会把“熊猫高级会所”这条数据搜索出来,是不是和你点外卖时的搜索场景很像?
3.2.8、哈希索引
哈希索引是等值查询时最快的索引,在之前MySQL篇章也提及过它,只不过MySQL-InnoDB引擎中,不支持手动创建哈希索引,只能由InnoDB运行时自动生成,即自适应哈希索引技术。反观MongoDB中,默认使用的索引结构为B+Tree,但它也支持手动创建哈希结构的索引,语法如下:
db.xiong_mao.createIndex({name:'hashed'});
我们只需要在创建索引时,在字段后显式指明hashed即可,这样在做等值查询时,就会自动使用哈希索引。
不过注意,哈希索引只支持等值查询的场景,如果一个字段还需要参与范围查询、排序等场景,那么并不建议在该字段上建立哈希索引。同时,创建哈希索引的字段,其值必须具备分散性,如年龄、性别这类字段,显然并不适合,大量重复值会导致哈希冲突十分严重,像手机号、身份证号这类属性的字段,就特别适合建立哈希索引。
3.2.9、通配符索引
在前面提到过“内嵌文档”这个概念,这是指将另一个文档,以字段值的形式嵌入到一个文档中。
结合MongoDB可以动态插入各种字段的特性,每个内嵌文档的字段,也可以灵活变化,例如前面给出的数据:
{_id:4, name:"黑熊", age:3, food:{name:"黄金竹", grade:"S"}},
{_id:5, name:"白熊", age:4, food:{name:"翠绿竹", grade:"B"}},
......
这些数据中都内嵌了一个food文档,虽然现在插入的都是固定的name、grade字段,但我们可以随时插入新的字段,例如:
db.xiong_mao.insertOne({
_id:99, name:"星熊", age: 1,
food: {name:"星光竹", grade:"S", quality_inspector: ["竹大","竹二"]}
});
这时新插入的文档,其food字段又多了一个quality_inspector质检员的属性,对于这种动态变化的字段,可不可以建立索引呢?答案是可以,MongoDB4.2中引入了“通配符索引”来支持对未知或任意字段的查询操作,创建的语法如下:
db.xiong_mao.createIndex({"food.$**": 1});
这时再通过food字段来进行查询,看看explain执行计划:
db.xiong_mao.find({"food.grade":"S"}).explain();
执行计划中很明显,通过food字段作为查询条件时,用到了刚刚创建的通配符索引。
最后,如果你想观察一个索引到底有没有效果,可以对比有索引、没索引时的查询耗时,但咱们需要把索引删掉吗?这是不需要的,MongoDB支持隐藏索引,可以把一个已有索引“藏”起来,相关命令如下:
// 创建隐藏索引
db.<集合名>.createIndex({<字段名>:<排序方式>}, {hidden: true});
// 隐藏已有索引
db.<集合名>.hideIndex({<字段名>:<排序方式>});
db.<集合名>.hideIndex("索引名称");
// 取消隐藏索引
db.<集合名>.unhideIndex({<字段名>:<排序方式>});
db.<集合名>.unhideIndex("索引名称");
OK,MongoDB基于索引查询时,同样也支持索引覆盖,也就是需要返回的结果字段,在索引字段中有时,会直接返回索引键的值,并不会再次回表查询整个文档。
3.3、explain执行计划
在之前的《SQL优化篇》中,曾详细说到过MySQL的explain工具,通过该命令,能有效帮咱们分析语句的执行情况,而MongoDB同样也提供了这个命令,在上面的索引阶段,也简单使用过,命令格式如下:
db.<collection>.find().explain(<verbose>);
explain方法同样有三个模式可选,这里简单列出来:
• queryPlanner:返回执行计划的详细信息,包括查询计划、集合信息、查询条件、最佳计划、查询方式、服务信息等(默认模式);
• exectionStats:列出最佳执行计划的执行情况和被拒绝的计划等信息(即语句最终执行的方案);
• allPlansExecution:选择并执行最佳执行计划,同时输出其他所有执行计划的信息;
一般排查find()查询缓慢问题时,可以先指定第二个模式,查看最佳执行计划的信息;如果怀疑MongoDB没选择好索引,则可以再指定第三个模式,查看其他执行计划,如果的确是因为走错了索引,这时你可以通过hint强制指定要使用的索引,如下:
db.集合名.find(查询条件).hint(索引名);
OK,接着来了解一下explain命令输出的信息含义,大家可以自行去mongosh里执行一下explain命令,会发现它输出了特别多的信息,咱们主要关注stage这个值,这是最重要的字段,就类似于MySQL-explain的type字段,代表着本次语句的查询类型,该字段可能会出现以下值:
• COLLSCAN:扫描整个集合进行查询;
• IXSCAN:通过索引进行查询;
• COUNT_SCAN:使用索引在进行count操作;
• COUNTSCAN:没使用索引在进行count操作;
• FETCH:根据索引键去磁盘拿具体的数据;
• SORT:执行了sort排序查询;
• LIMIT:使用了limit限制返回行数;
• SKIP:使用了skip跳过了某些数据;
• IDHACK:通过_id主键查询数据;
• SHARD_MERGE:从多个分片中查询、合并数据;
• SHARDING_FILTER:通过mongos对分片集群执行查询操作;
• SUBPLA:未使用索引的$or查询;
• TEXT:使用全文索引进行查询;
• PROJECTION:本次查询指定了返回的结果集字段(投影查询);
这里咱们只需要带SCAN后缀的,因为其他都属于命令执行的“阶段”,并不属于具体的类型,explain会将一条语句执行的每个阶段,都详细列出来,每个阶段都会有stage字段,我们要做的,就是确保每个阶段都能用上索引即可,如果某一阶段出现COLLSCAN,在数据量较大的情况下,都有可能导致查询缓慢。
其次,咱们需要关心keysExamined、docsExamined两个字段的值(exectionStats模式下才能看到),前者代表扫描的索引键数量,后者代表扫描的文档数量,前者越大,代表索引字段值的离散性太差,后者的值越大,一般代表着没建立索引。
OK,这里暂时了解这么多,关于explain其余的输出信息,很多跟集群有关系,为此,等后续把MongoDB集群过了之后,有机会再详细讲述~
四、MongoDB安全与权限管理
通常为了保证数据安全性,Redis、MySQL、MQ、ES……,通常都会配置账号/密码,一来可以提高安全等级,二来还可以针对不同库、操作设置权限,极大程度上降低了数据的安全风险。同样,在MongoDB中也支持创建账号、密码,以及分配权限,并且还支持角色的概念,可以先为角色分配权限,再为用户绑定角色,从而节省大量重复的权限分配工作。
同时,MongoDB中还内置了大量常用角色,方便于咱们快速分配权限,不过并没有默认的账号,所以想要启用MongoDB的访问控制,还需要先创建一个账号:
// 切换到admin数据库
use admin;
// 创建一个用户,并赋予root角色(root角色只能分配给admin库)
db.createUser({"user":"zhuzi", "pwd":"123456", "roles":["root"]});
// 退出mongosh客户端
quit;
接着再关闭MongoDB服务,重新启动时开启访问控制,必须使用账号密码连接才允许操作:
[root@~]# /soft/mongodb/bin/mongod -shutdown -f /soft/mongodb/conf/standalone/mongodb.conf
[root@~]# /soft/mongodb/bin/mongod -auth -f /soft/mongodb/conf/standalone/mongodb.conf
[root@~]# /soft/mongodb/mongosh/bin/mongosh 192.168.229.135:27017
或者这里也可以直接修改配置文件:
[root@~]# vi /soft/mongodb/conf/standalone/mongodb.conf
# 在配置文件结尾加上这两行
security:
authorization: enabled
然后通过不带-auth的命令启动,效果同样是相同的。
接着先切换到咱们前面创建的zhuzi库,查询一下xiong_mao集合试试看:
use zhuzi;
db.xiong_mao.find({_id:1});
MongoServerError: command find requires authentication
此时就会看到对应报错,提示目前未授权,所以无法执行命令,因此这里需要登录一下,不过登录必须要切换到admin库下才可以,否则会提示认证失败:
db.auth("zhuzi","123456");
{ok:1}
use zhuzi;
db.xiong_mao.find({_id:1});
[{_id:1,name:'肥肥',age:3,hobby:'竹子',color:'黑白色'} ]
认证成功后,再次切回zhuzi库查询,此时会发现数据依旧可以查询出来。
当然,如果不想每次连接时都切换到admin库下登录,然后再切换回来,此时可以在zhuzi库下再创建一个用户,如下:
// 先切换到zhuzi库
use zhuzi;
// 再在zhuzi库下创建一个zhuzi用户,并分配dbOwner角色
db.createUser({"user":"zhuzi", "pwd":"123456", "roles":[{"role":"dbOwner", "db":"zhuzi"}]});
// 退出连接
quit;
然后可以再次连接MongoDB服务,这时直接切换到zhuzi库下登录后,也照样可以读写数据,而关于上述命令中分配的dbOwner角色是什么意思呢?后面会说明。
4.1、MongoDB内置角色
前面大致了解了一下如何启用访问控制后,接着来看看MongoDB中的内置角色,毕竟前面只使用了root角色,可以通过下述命令来查询MongoDB所有内置角色:
use admin;
db.runCommand({rolesInfo: 1, showBuiltinRoles: true});
返回结果较长,这里就不贴了,大家可以自己执行一下,这里归类一下:
• root:超级管理员权限,可以执行任何操作;
• read:只读用户,不允许对数据库执行写入操作;
• readWrite:读写用户,允许对数据执行读写操作;
• dbAdmin:数据库管理员(如创建和删除数据库),不允许读写数据;
• userAdmin:用户管理员(如创建和删除用户),不允许读写数据;
• dbOwner:同时拥有dbAdmin、userAdmin两个角色的权限,且允许读写数据;
• backup:具有备份和恢复权限,不允许读写数据;
• restore:只具有数据恢复权限,不允许读写数据;
• clusterAdmin:集群超级管理员,可以执行集群中任意操作,允许读写数据;
• clusterManager:集群管理员,只可以管理集群节点、配置等;
• clusterMonitor:集群监视员,允许监控集群的状态和性能,不允许读写数据;
上面是一些常用的角色,而对于其他使用频率较少的则不再列出,而这些内置角色,可以在创建用户的时候分配,一个用户同时可以绑定多个角色。但如果你想要的权限,内置角色并不提供,也可以自定义角色,下面来看看。
4.2、MongoDB自定义角色
先来看看自定义角色的语法:
use zhuzi;
db.createRole({
// 自定义角色的名称
role:"zhuziRole",
// 自定义角色拥有的权限集
privileges:[
{
// 自定义角色可操作的资源
resource:
{
// 当前角色可操作zhuzi库
db:"zhuzi",
// 当前角色具体可操作的集合(多个传数组,所有写"")
collection:""
},
// 当前角色拥有的权限
actions:["find","update","insert","remove"]
}
],
// 当前角色是否继承其他角色,如果指定了其他角色,当前角色自动继承父亲的所有权限
roles:[]
});
关于该命令中的具体含义,大家可以参考上面的注释,通过该方式,诸位可以灵活的创建出各种适用于业务的角色,最后再附上一些相关命令:
// 给指定角色增加权限
db.grantPrivilegesToRole(
"角色名称",
[{
resource:{
db:"库名",
collection:""
},
actions:["权限1","……"]
}]
);
// 回收指定角色的权限
db.revokePrivilegesFromRole(
"角色名称",
[{
resource:{
db:"库名",
collection:""
},
actions:["权限1","……"]
}]
);
// 删除角色(要先进入角色所在的库)
use zhuzi;
db.dropRole("角色名称");
// 查看当前库的所有角色
show roles;
// 查看当前库中所有用户
show users;
OK,掌握上述这些命令完全能满足日常需求了,至于其他更多的,则可以参考官网或自行查阅资料。
五、MongoDB入门篇总结
到这里,MongoDB入门篇内容就结束了,原本打算一篇写完,结果发现这篇就有好几万字了,由于平台字数限制,所以拆成了三篇来写,每一篇分别对应不同的学习阶段,上篇写入门、中篇写进阶、下篇写
当然,虽然这篇字数最多,但大多数在讲API应用,因此阅读难度并不算大,更多考验的是耐心,如若你有耐心阅读至此,那么恭喜你!又掌握了一项新的技术栈~

