布隆过滤器是一种空间效率高和时间效率高的概率型数据结构,用于判断某个元素是否在一个集合中。它通过多个哈希函数将元素映射到一个位数组中,虽然能快速判断元素是否存在,但有一定的误判率,即可能会误认为元素存在,但不会漏掉实际存在的元素。
在现代前端开发中,获取屏幕的宽度和高度通常依赖于 JavaScript。然而现代 CSS 也可以获取到屏幕的宽高,通过自定义属性(CSS Variables)和一些数学函数来实现这一目标。本文将详细解析如何使用 CSS 的 @property 规则和一些数学运算来获取屏幕的宽高,严格的说是获取视口的宽度和高度。
文章内容是在小红书上很火的,关于成长,关于人性的潜规则。 每一条深度下来都让人值得反思,值得我们去深度。 从学校走出来不能再带有那般的稚嫩,下面的30条也是成年人经过血的教训才懂的道理。希望你能通过本文能更加开朗。例如关于朋友:真正的朋友,一定会越来越少, 因为走着走着,方向就不一致了, 性格就不相同了,地位有悬殊了, 所以不用在乎失去了谁, 而是应该珍惜还剩下谁。
本文将详细探讨Golang中实现服务器发送事件(Server-Sent Events, SSE)和WebSocket通信协议的方法。我们将讨论它们的工作原理,对比它们的优缺点,并提供详细的代码示例来演示如何在Golang应用中使用这两种技术。
在Go语言的错误处理机制中,panic和recover 是两个强大而独特的工具。它们为开发者提供了一种处理异常情况的方式,有别于传统的try-catch结构。本文将深入探讨panic和recover 的工作原理、使用场景,以及如何巧妙地运用它们来提高代码的健壮性和可维护性。
在漫长的人生旅途中,我们都在不断地探索、追寻,努力寻找那个最真实、最完整的自我。因为只有真正了解自己,才能战胜内心的种种困惑与恐惧,进而战胜外在的一切挑战与困难。自我认识,是每个人成长的必经之路,也是走向成功的第一步。
前端页签之间通信的六种方法。为了提高稳定性,每个标签页都是一个独立的浏览器上下文,它们之间是相互隔离的,一个标签页崩溃不会影响到其他标签页,无法直接访问对方的数据或进行通信。
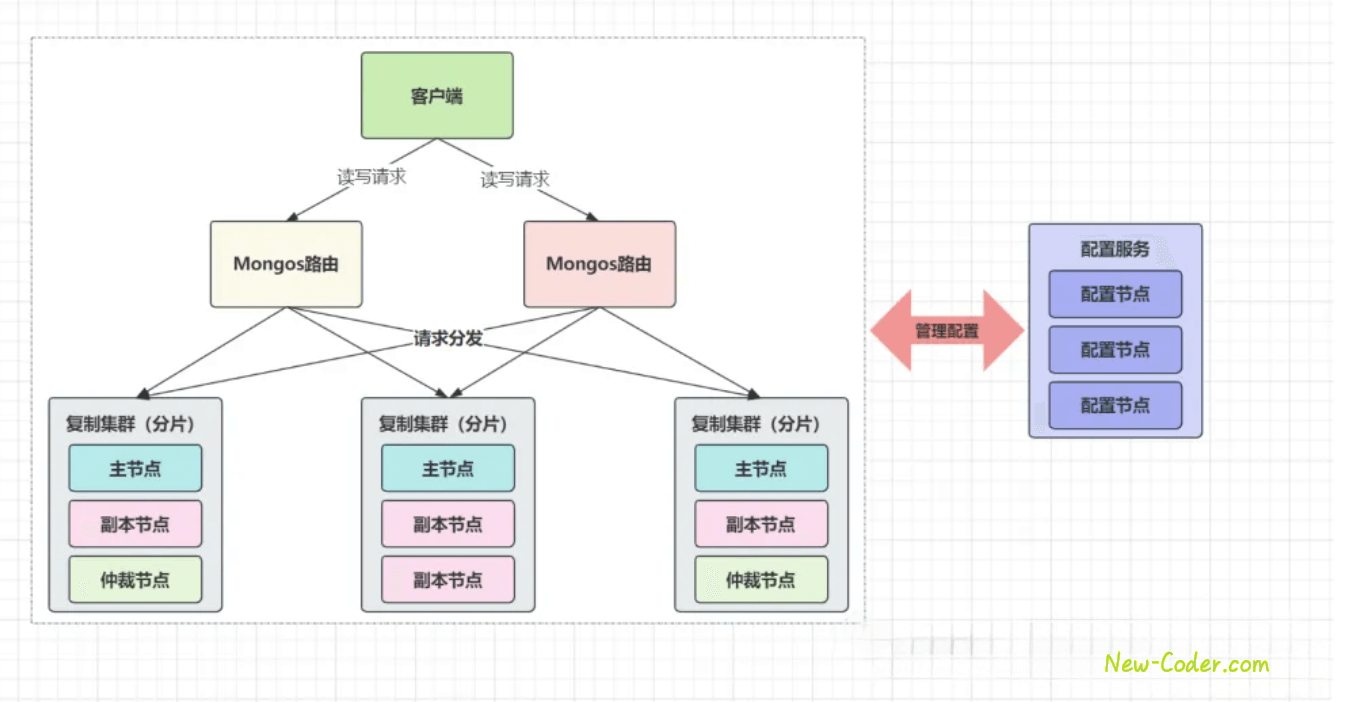
在上一篇关于《MongoDB入门》的文章中,咱们把单机版的MongoDB讲了个大概,但很多情况下,单节点服务往往并不能满足系统需求,毕竟单节点部署的方式有很多隐患:没有灾备能力,吞吐量不够, 拓展性不足,本文讲继续大家学习MongoDB高可用性。
MongoDB是数据库家族中的一员,是一款专为扩展性、高性能和高可用而设计的数据库,它可以从单节点部署扩展到大型、复杂的多数据中心架构,也能提供高性能的数据读写操作;而且提供了数据复制、无感知的故障自动选主等功能,从而实现数据节点高可用。
本文主要介绍一些常用的Linux性能工具,这些工具可以帮助系统管理员和开发人员监控、分析和优化系统性能。文中梳理常见的性能工具,从 CPU、内存、文件系统和磁盘 I/O、网络以及基准测试等不同的角度,汇总了各类性能指标所对应的性能工具速查表。